VMware Private AI Foundation with NVIDIA is VMware’s flagship approach to bringing generative AI and LLMs directly into the enterprise data center, without sending a single token, document, or conversation to a public cloud model. If you have sensitive data, compliance requirements, or a leadership team that would faint at the idea of “AI in the cloud,” this is the model that makes sense.
The big deal:
Private AI is baked directly into VMware Cloud Foundation 9.0+ and is easy to deploy.
This is not a bolt-on product. It is part of the platform you already operate.
VMware and NVIDIA co-engineered this stack so enterprises can run modern AI workloads at near–bare metal GPU performance, while using the exact same tools we’ve used for twenty years: vSphere, vCenter, DRS, HA, vMotion, NSX, and Tanzu.
If you know VMware, you already know 80 % of Private AI, so let’s take a closer look.
What VMware Private AI Actually Includes
Think of it as the full AI lifecycle delivered as a native VMware service:
A governed, enterprise grade Model Store
Versioning, RBAC, approval workflows, NVIDIA models, community models, or your own fine-tuned models, all in one place.
NVIDIA powered inference with one click endpoints
Using NIM microservices and TensorRT-LLM under the hood. Sub-100 ms latencies on Blackwell GPUs are real.
A production RAG stack out of the box
PostgreSQL + pgvector for vector search, NeMo Retriever for embeddings, and a Data Indexing Service that automatically ingests your enterprise content: PDFs, Office docs, Confluence, SharePoint, and more.
Low code Agent Builder
Build internal AI agents that can call APIs, execute workflows, and automate IT or business processes without having to reinvent the orchestration stack.
An OpenAI compatible API gateway
Drop in replacement for public model endpoints. Add OAuth/JWT auth, rate limiting, and routing without rewriting apps.
Deep integration with vSphere
DRS manages GPU placements, vMotion moves inference VMs live, HA protects GPU hosts, and NSX gives you micro segmentation for your east-west traffic.
Fully offline / sovereign cloud ready
NGC mirror support means you can run Private AI inside disconnected or regulated environments.
If you’re thinking “this looks like the enterprise version of running LLMs in VSAN clusters,” you’re not wrong — except now it’s production-ready and fully NVIDIA-validated.
The NVIDIA Stack Under the Covers
Enterprises constantly underestimate the gravitational pull of what’s happening below the UI. The NVIDIA Stack Under the Covers is exactly that force in VMware Private AI. It’s the same software foundation the hyperscalers run when they stand up GPU data-center clusters, except here it’s been hardened, validated, and packaged for on-prem and sovereign cloud realities by VMware and NVIDIA.
Instead of isolated components, this stack operates like a coordinated cluster. NIM microservices provide containerized inference endpoints that behave like modular AI APIs you actually control, engineered for speed and repeatability. TensorRT-LLM compiles and runs transformer models with full-GPU awareness, squeezing out latency and unlocking throughput gains that enterprises desperately need as model sizes balloon. NeMo Retriever handles embeddings with a level of quality that materially impacts retrieval accuracy, making RAG pipelines feel sharper and more reliable instead of “close enough.”
Then you have the quiet workhorses that ops teams rarely think about until the moment something breaks. GPU and Network Operators automate drivers, firmware, and RDMA networking so clusters can speak at wire speed without humans babysitting every node. Triton Inference Server steps in like a multi-model control plane, built to serve more demanding inference workloads without collapsing under complexity. DCGM collects real-time GPU telemetry at the hardware layer, exporting operational truth instead of vibes. No theories, no hypotheticals, just metrics, drivers, and networking behaving like they should.
And the part that matters most to me? This isn’t a vendor glue job. Every layer is jointly validated by VMware and NVIDIA, from GPU drivers to performance tuning to RDMA network behavior. It’s designed to move as one system, which is the only way Private AI works in the enterprise long term. When AI has to come to your data, you don’t get points for imagination, you get points for infrastructure that shows up consistently, scales predictably, and doesn’t exploit your team’s sanity in the process.
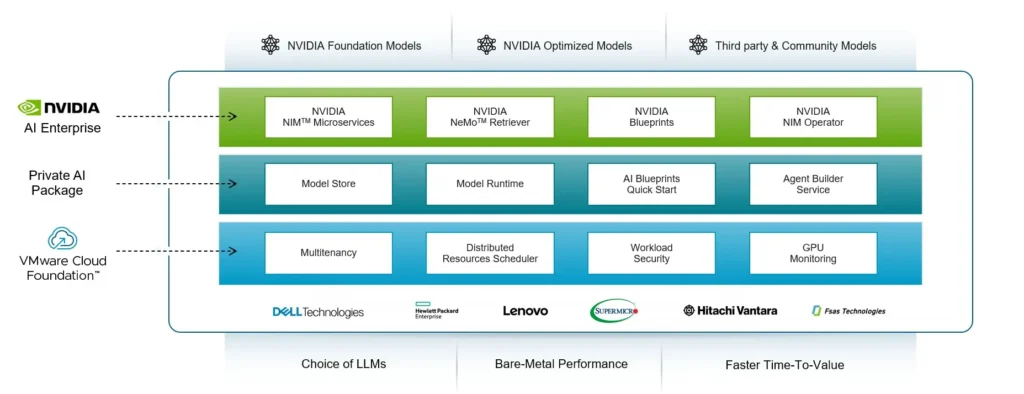
From the Private AI Services: New in VMware Private AI Foundation with NVIDIA in VMware Cloud Foundation 9.0 blog)
Reference Architectures To Get You Started
It’s no secret that I am a big fan of reference architectures, so here are a few VMware and NVIDIA fully tested blueprints for you to look at to get up and running quickly.
1. Private AI Ready Infrastructure for VCF
This is the “baseline” validated design that shows enterprises exactly how to stand up an AI-ready workload domain inside VMware Cloud Foundation. It covers everything from GPU host configuration and vSphere settings to Tanzu Kubernetes clusters, networking, storage, and NVIDIA NIM deployment. Think of it as the official, step-by-step blueprint for running production-grade LLMs and RAG workloads on VCF — the closest thing to a vendor-supported IKEA manual for Private AI.
2. Generative AI RAG Reference Design
This blueprint gives you a turnkey way to deploy a complete enterprise RAG stack on VMware. It covers model hosting, vector databases, embedding pipelines, data ingest, retrieval logic, and the inference endpoint, all pre-tested on NVIDIA GPUs. The value here is speed: organizations routinely go from zero to a fully functional, domain-specific chatbot or knowledge assistant in hours instead of weeks.
3. HGX H100/H200 8-GPU Scale-Out Architecture
This design is all about high-performance, multi-node GPU clusters built on NVIDIA’s HGX platform. It covers NVLink/NVSwitch topologies, multi-GPU fine-tuning, distributed inference, and how to scale out to rack-level compute for heavy workloads. Enterprises use this blueprint when they need the kind of power that looks and feels like a mini SuperPOD — but inside a VMware-managed environment.
If you happen to be a VMware Cloud Service Provider (VCSP), this isn’t a refernce architecture, but a blog focused on on VCSP + Sovering Cloud with VMware Private AI.
Why Enterprises Choose Private AI
Personally, I think this stuff is cool, and you probabkly do too if you’re reading this, but we need to dive deeper into the business case. Why would organizations want Private AI? Here are the things that are top of mind:
1. True data sovereignty
No prompts, embeddings, or fine-tuning data leave your environment.
2. Bare metal performance
Virtualization overhead is sub-3 % on modern GPUs. That’s negligible.
3. Lower TCO than public cloud LLMs
No per-token fees. No egress charges. No unpredictable model costs.
4. Operational familiarity
Your teams already know the tools. No retraining. No separate platform.
5. Fast time-to-value
Most customers spin up a production RAG chatbot in under a week.
6. Secure multi-tenancy
Share infrastructure safely across departments — or external customers.
A Shockingly Simple Getting-Started Path
If you already run VCF, you’re almost there. All you need to do is:
- Enable Private AI Services in SDDC Manager.
- Deploy NVIDIA GPU and Network Operators (automated in the blueprint).
- Sync or import your models.
- Deploy a validated blueprint (e.g., Llama 3.1 70B RAG).
- Monitor everything through vCenter like you always have.
Realistically? Seasoned vSphere teams will have this up in running in just a few days.
Disclaimer: The Power Problem
One thing I cannot stress enough: do not order GPUs until you’ve validated your power and cooling requirements and capabilities. Adding AI hardware isn’t like adding another ESXi host, because these servers are loaded up with GPUs that draw power and expel heat.
The Bigger Strategic Picture
Private AI is not just about running models inside your own walls. It removes vendor lock-in and eliminates the unpredictability of token-based pricing. It allows you to fine-tune models on proprietary data in a safe and controlled environment. It also meets the strictest regulatory requirements, including GDPR, HIPAA, FedRAMP, IRAP, and national data residency laws, which makes it viable in industries where cloud-based AI is simply not an option. Private AI gives you predictable performance and reliable latency, which matters once you start putting real workloads behind these systems. Most importantly, it aligns with where global AI governance is headed. The future standard is clear: AI must come to your data, not the other way around.
Where Most Organizations Go From Here
Most enterprises start their Private AI journey with a simple goal: get something real running. A chatbot. A document assistant. An agent that can automate internal workflows. With VMware Private AI, those use cases are not six-month science projects. They are week-one deliverables.
What really differentiates successful adopters is what happens after that first win. They begin treating Private AI not as an experiment but as part of their core infrastructure strategy. They build GPU capacity plans. They modernize data pipelines. They standardize model governance. And they start asking better questions: Which teams get GPU priority? What data becomes indexable? What processes are ready for agent automation?
This is where VMware Private AI shines. It gives you a path to grow from “let’s try AI” to “AI is part of how we operate,” without ripping out your existing stack or retraining the whole organization.
If you are already running vSphere or VCF, the next steps are straightforward: validate power and cooling, choose your reference architecture, deploy your first model, and build your first real use case. You do not have to boil the ocean to get value. Just get one workload running and let the momentum pull you forward.
Note: This post was originally posted on vMiss.net